如何做好 openGauss 企業級部署?
原始 twt社區 twt企業IT社區 2023-12-29 07:35 發表於海南
圖片
【摘要】openGauss資料庫作為開源資料庫的後起之秀,這兩年蓬勃發展,關於其細緻的安裝教程,網路上並不缺少,但其作為新的資料庫,如何做好企業及部署,這是值得探討的方向。 本文結合商業資料庫應用與部署的經驗,討論openGauss資料庫企業級應用需求下需要考慮的方方面面,具有獨特的參考價值。
【作者】孔再華,具有豐富的資料庫環境問題診斷與效能調優的經驗。 在資料庫同城雙活,集群,多分區,分佈式等項目實施上具有豐富的經驗。 現任職於某股份制銀行科技部,工作致力於資料庫同城雙活架構建設,資料庫分散式架構建置與資料庫智慧維運(AIOps)方向。 對於如何將AI技術運用在維運領域具有濃厚的興趣和創新熱情。
openGauss資料庫作為開源資料庫的後起之秀,這兩年開源社群蓬勃發展,越來越多的公司和企業加入openGauss開源社群。 作為純國產開源的關係型資料庫,目前部分銀行已經嘗試在生產應用openGauss資料庫,同時也有許多合作夥伴在openGauss核心的基礎上推出各自的商業版本。
openGauss資料庫至今為止基本上保持三月一次發版的節奏。 每次發版都會發現內容非常多,不僅包含大功能的新增和改進,同時也有非常多的問題被修復。 可以說openGauss開源社群的投入,並不遜色於傳統的大型商業資料庫公司。 國內幾家合作夥伴的加入與貢獻,也讓openGauss資料庫生態越來越好,也為企業在生產使用openGauss資料庫帶來更大的信心。
作為新的資料庫,如何做好企業及部署,這是值得探討的地方。 這篇文章並不是一個細緻的安裝教程,網路上也不缺乏該類教程,而是結合商業資料庫應用和部署的經驗,討論下openGauss資料庫企業級應用需求下需要考慮的方方面面。
資料庫結構定義設計
openGauss作為集中式的單機資料庫,這裡的架構設計主要是討論高可用怎麼做,同城和異地容災怎麼做。
本地高可用
傳統的資料庫本地高可用有兩種比較流行的方式:集中式儲存方式和資料庫複製方式。 Db2和Oracle等商業資料庫的部署大多都是採用集中式儲存的模式。 而MySQL資料庫基本上就是透過資料庫複製的模式來實現高可用。
集中式儲存
集中式儲存方案是目前企業級部署中應用最廣泛且最成熟的方案。 資料庫的資料部署在儲存上,上層透過系統的HA工具監控和切換。 然而這種方式也有缺點。 首先是外置儲存的效能和內建SSD碟的效能差異在資料庫應用場景對比還是比較明顯的。 其次是磁碟資料的損壞需要透過資料庫復原來修復,相對恢復時間較長。 最後從部署成本來說,集中式儲存方案部署較重,需要儲存佈線等。
資料庫複製
資料庫複製方案是透過資料庫日誌的實體或邏輯同步,在備機即時重做主機的修改,從而確保主備資料庫的資料一致性。 這也是一個非常成熟的方案。 Db2和Oracle等商業資料庫都有基於資料庫日誌物理同步的功能。 MySQL的日誌邏輯複製也應用非常廣泛。 這種方案下資料庫主機上的儲存採用內建磁碟,主備的資料是完全隔離的,更好的利用了內建磁碟的效能和做到了儲存上的隔離。
openGauss資料庫也支援資料庫日誌的實體複製和邏輯複製。 邏輯複製存在一個比較重大的缺點,就是對於大交易的資料回放效能不好。 因此在openGauss資料庫的高可用設計中,資料庫日誌物理同步是目前最好的方案。
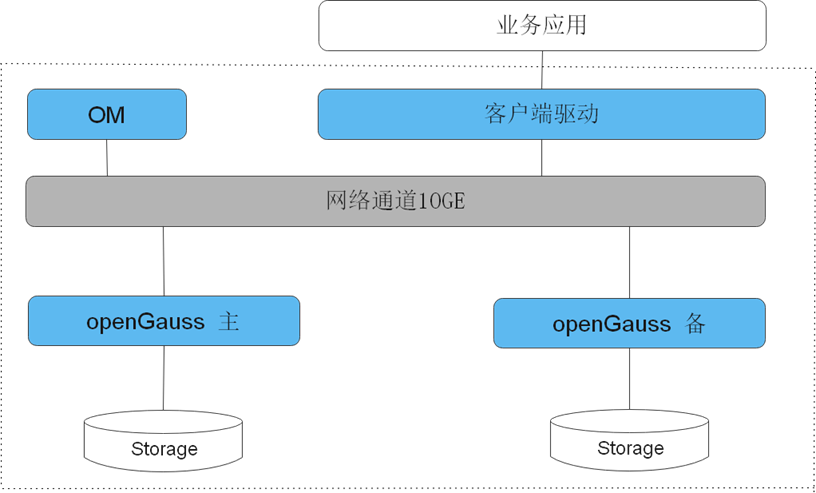
官方的架構圖也是建議使用這種方式。 openGauss資料庫提供了om工具來幫助部署和管理openGauss資料庫的主備叢集節點。 openGauss資料庫的實體複製支援一主多備和級聯備等功能,未來也會加入延時複製功能。 openGauss的備機是支援唯讀操作的,可以實現讀寫分離,減少主函式庫的讀負載。
建議本地高可用就透過資料庫物理同步來實現。 建議開啟備機可讀,設定wal_level為hot_standby。 為了保障資料一致性,synchronous_commit建議修改為remote_write或remote_receive。 如果只有一主一從的情況下,建議設定most_available_sync為on。 最後透過第三方的高可用叢集軟體來監視openGauss的主從狀態,實現故障自動切換等高可用情境。
客戶端存取方式
openGauss資料庫主從架構下,客戶端如何連接到主資料庫? 又怎麼做讀寫分離? 這時候就需要討論下客戶端連接資料庫的幾種方式:VIP,DNS和主機清單。 因為openGauss資料庫的jdbc驅動裡支援設定多個主機,並提供參數設定只連主節點還是只連備節點,這也應對了讀寫分離的需求。
VIP
傳統的VIP模式只能支援應用程式連接到主節點上,從節點的讀取請求是不太好設定的。 增加讀取VIP的管理對於高可用軟體來說就太複雜了。 VIP管理還有一個限制是必須屬於同一網段。 對於同城雙中心不能採用相同網段的情況下,VIP漂移就不能實現。
DNS
DNS也具備高可用性,但只能偵測到機器IP是否存在,無法偵測openGauss的服務,所以採用DNS的高可用相對來說不太適合資料庫來使用。
主機列表
例如下面這個範例就是只連主庫的客戶端設定:
url=jdbc:postgresql://:26000,:26000/?connectTimeout=5&targetServerType=master&tcpKeepAlive=true
我比較偏向採用主機清單的方式,透過設定客戶端參數,實現自動主庫發現,負載平衡,只讀從庫等各類應用場景需求。 這種方式也避免了VIP,DNS在不同架構下的管理複雜性,相對更通用一些。 缺點是增加了一點客戶端資料來源配置的複雜性。
同城容災
資料庫級的同城容災可能會分成不同的等級來實現。 金融業的同城資料中心一般都要求具備全量承載資料和業務的能力。 資料庫實現同城容災最主要目標是最小化RPO和RTO指標,在此基礎上可能還會有同城災備資料庫的唯讀存取等需求。 同城容災的實現方式也有兩種主流模式:儲存複製和資料庫複製。 優缺點和本地高可用差不多。 但如果本地openGauss採用了內建磁碟部署,那麼也就不支援做儲存複製的容災模式了。 所以建議openGauss資料庫還是採用資料庫複製的方式。 注意在設定synchronous_standby_names的時候要確保同城至少有一個節點處於資料同步狀態。
這裡稍微討論下同城容災的幾個定位:
1.同城是否需要保障RPO=0?
金融業的大部分需要做同城容災的應用都要求RPO=0,不能容忍同城切換遺失資料。 因此在設計synchronous_standby_names的時候需要加上同城備機並設定成同步模式。 然而雙中心間的網路穩定性顯然比同中心要差很多,為了避免設定了強同步後,雙中心網路抖動可能會影響主機效能,可以考慮設定most_available_sync參數為ON,遺失備機的情況下主機 可以斷開備機並恢復工作。
2.同城資料庫是否需要只讀存取?
資料庫的備機提供唯讀存取的能力,包括同城的資料庫備機。 那麼是否真的需要去啟用這個功能呢? 從前端業務的性能考慮,顯然同機房訪問要比跨機房訪問要更快一些。 而從後端資料庫的處理能力來說,需要只讀能力擴展的需求,都是為了滿足減輕主庫的運作壓力,也要求應用程式能夠配置單獨的唯讀資料來源,從應用層就解決好讀 寫分離。 在這些場景需求裡,顯然本地的備機只讀訪問就可以解決這些問題,所以大概率是不需要升級到同城只讀訪問的性能擴展需求的。 只有一種情況下需要同城只讀訪問,那就是為了架構的便利性,同城切換的便利性等需求。 這種情況並不是以擴展效能為目的,而是以技術架構方案的整體性設計需求。
3.同城是否需要自動切換?
這個問題一直是討論的比較多的地方。 保守一點的想法是同城切換都是交給人工來決策的。 激進一點的想法是同城都保障不丟資料庫,當然也可以自動切換,交給HA監控並自動化切換修復多好。 所以面對不同的選擇,這裡對於同城的定位就不一樣,所涉及的HA架構設計也很不一樣。 個人認為除非同城雙中心定位完全無主次之分,否則大部分應用還是偏向於運行在主機房,這種情況下,同城切換適合交給人為決策,自動化平台快速實現。
異地容災
異地容災也需要分不同的資料保護類型。 可能最關鍵的應用也就是盡可能減少RPO和RTO。 這種類型的關鍵應用也是建議透過資料庫主從複製的方式來實現,只是異地的資料庫節點通常都是設定為非同步模式。
openGauss資料庫支援級聯備,也就是從一主多從的某個從庫上,配置一個級聯備機,指向異地容災的資料庫從庫。 這也是比較推薦的方式,減少主庫的壓力。
使用者規劃設計
這裡主要討論下安裝部署裡的作業系統用戶,資料庫使用者等規劃設計。
系統用戶
作業系統使用者主要是安裝openGauss的使用者和群組,以及需要使用gsql客戶端存取openGauss資料庫的作業系統使用者。 例如華為的openGauss資料庫預設採用omm用戶和dbgrp用戶群組,這在華為的高斯分散式產品裡都是這個設計的。 我們使用openGauss的時候也延續了這個習慣。
超級用戶
omm作業系統使用者俱有openGauss資料庫程式的存取權限,能執行gsql、gs_ctl等工具。 而這些工具的權限一般是700,也就是說只有omm用戶能使用。 而通常omm用戶訪問本地的openGauss是透過socket,可以使用超級用戶,還可以免密,因此這個用戶完全是交給系統管理員的,不適合交給用戶使用。
應用程式用戶
那如果應用程式使用者需要使用gsql等工具怎麼辦? 這種情況建議設計一個系統使用者appuser,並為它安裝一個單獨的gsql等工具客戶端,透過IO連接資料庫。
資料庫用戶
資料庫使用者也應該分為幾種類型:超級管理員、監控管理員、資料庫管理員和普通資料庫使用者。
超管理員
一開始initdb的初始用戶就是超級管理員用戶,具有sysadmin的權限。 這個使用者通常不會交給應用程式來使用,甚至不應該當作超級管理員來使用。 這個使用者只能是作為能夠登入這個作業系統上應急的免機密超級使用者。
所以為了管理openGauss資料庫,我們還需要建立一個單獨的管理員使用者俱備sysadmin角色權限。 例如設計一個gsadmin用戶,在維運工具平台透過這個用戶遠端管理所有的openGauss資料庫。
create user gsadmin with sysadmin password ‘xxxxxxxx’
還有一種用戶是遠端備份用戶,建議建立單獨的用戶並sysadmin角色權限。
監控管理員
openGauss資料庫從2.0.0版本開始提供了monadmin角色。 這個角色權限能夠存取所有的系統視圖。 因此對於監控用戶,建議配置這個角色即可。
create user monadmin with monadmin password ‘xxxxxxxx’
資料庫管理員
openGauss的資料庫是相互隔離的。 對於每一個獨立的資料庫,可以設定一個資料庫管理員角色的用戶,給予全庫的管理權限。
grant all privileges on database
這種用戶通常也是作為應用程式來連結的用戶,具備全庫的物件管理能力,也具備資料修改查詢能力。 這是很常見的用法, 很少在應用資料來源設定連線使用者的時候還繼續做細緻的權限分離。 當然資料庫權限管理是具備相關能力的。
普通資料庫用戶
除了本應用系統使用的資料庫管理員用戶,可能還有類似跨系統存取的特殊需求情況。 例如抽取資料的用戶,只讀訪問的用戶等。 這些使用者建議建立單獨的最小授權使用者。
白名單
在openGauss資料庫的目錄下,設計了pg_hba.conf設定文件,用來定義使用者存取資料庫的方式,也可以稱為白名單管理。 定義了在什麼訪問類型下,訪問哪個資料庫,是哪個用戶,從哪裡來訪問,採用何種驗證方式。 這些組合可以實現很複雜的白名單過濾規則。 這種可以過濾IP的用戶存取控制有點像mysql,但又完全不一樣。 openGauss裡的資料庫使用者名稱對應的就是一個使用者角色,不像mysql,如果使用者名稱裡的IP不一樣,其實算是不同的使用者。
不過從金融業的實務來看,資料庫伺服器和應用伺服器等在隔離的網路區內,主機間的存取控制透過網路來管理,基本上不需要底層資料庫來實現複雜的管控。 為了管理方便,不如全部放開資料庫層級的ip管控。 下面這個範例使用gs_guc工具來設定整個叢集所有的白名單:
gs_guc reload -N all -I all -h “host all all 0.0.0.0/0 sha256”
翻譯過來就是任何IP基於host請求過來的所有用戶存取所有資料庫都採用sha256加密演算法驗證用戶。
檔案系統設計
openGauss資料庫建議配置至少兩個獨立的檔案系統。 一個用來放資料庫,一個用來放資料庫運行中產生的歸檔日誌,診斷日誌等。
資料庫
資料庫存放的路徑建議放在單獨的檔案系統上。 部分重要的業務系統也建議將線上日誌pg_xlog放在單獨的檔案系統上,與資料data分開。 然而從實際情況來看,data和xlog採用不同的檔案系統,除非底層的磁碟也是獨立的,效能是沒有什麼差別的。 因此暫時建議採用一個就可以了。
診斷日誌
資料庫運行中產生的診斷日誌,審計日誌,歸檔日誌,core文件等,都是不影響資料庫運行的,但是又持續不斷的產生的。 因此需要單獨規劃一個檔案系統來存放,同時做好這些日誌的清理策略。 這個文件系統也可以用來規劃存放腳本文件,備份文件,跑批文件等臨時文件。
例如將歸檔日誌路徑、稽核日誌路徑、core檔案路徑和診斷日誌路徑都設定到這個檔案系統下面。
gs_guc set -c “archive_command = ‘cp %p /gausslog/archive/%f'”
gs_guc set -c “audit_directory=’/gausslog/log/omm/pg_audit'”
gs_guc set -c “bbox_dump_path=’/gausslog/corefile'”
gs_guc set -c “log_directory=’/gausslog/log/omm/pg_log'”
其他維運設計
規劃好了資料庫安裝,下一步就是設計相關維運需求方案。
性能參數設定
安裝完成之後最先需要的是根據業務負載需求設定相關參數。 這些參數細節比較多,需要好好閱讀相關資料再做選擇。 其中max_process_memory和shared_buffers是比較關鍵的記憶體參數,建議依照作業系統記憶體總量(資料庫獨佔資源)的70%和50%來設定。
增量檢查點和雙寫開關應該要打開。 這是openGauss相對於postgresql比較大的改進機制,解決了全量檢查點的效能瓶頸問題。 enable_opfusion開關也建議打開,對於高並發小事務的競爭會有改善。
gs_guc set -c “cstore_buffers = 128MB”
gs_guc set -c “enable_alarm = off”
gs_guc set -c “enable_delta_store = on”
gs_guc set -c “enable_double_write = on”
gs_guc set -c “enable_incremental_checkpoint = on”
gs_guc set -c “enable_wdr_snapshot = off”
gs_guc set -c “enable_xlog_prune = on”
gs_guc set -c “log_min_duration_statement = 1s”
gs_guc set -c “maintenance_work_mem=1GB”
gs_guc set -c “max_connections = 2000”
gs_guc set -c “max_files_per_process = 10000”
gs_guc set -c “max_prepared_transactions = 2000”
gs_guc set -c “session_timeout = 0”
gs_guc set -c “shared_buffers = 2GB”
gs_guc set -c “temp_buffers = 128MB”
gs_guc set -c “update_lockwait_timeout = 1min”
gs_guc set -c “wal_buffers = 64MB”
gs_guc set -c “wdr_snapshot_interval = 10min”
gs_guc set -c “work_mem = 512MB”
gs_guc set -c “log_temp_files = 100MB”
gs_guc set -c “enable_mergejoin = ON”
gs_guc set -c “enable_nestloop = ON”
gs_guc set -c “advance_xlog_file_num = 10”
gs_guc set -c “pagewriter_sleep = 1000ms”
gs_guc set -c “xloginsert_locks = 50”
gs_guc set -c “lockwait_timeout = 1min”
gs_guc set -c “enable_opfusion = off”
gs_guc set -c “max_process_memory=3GB”
自動管理
為了降低DBA的維運工作量,使用openGauss的流程要充分利用好資料庫的自動管理機制。 尤其是跟性能動態調整相關的機制。
自動統計資訊收集分析
openGauss資料庫內部的執行計劃有兩種選擇方式,基於規則和基於代價。 基於代價的這種方式依賴資料庫的統計資訊。 資料庫的統計資訊是由analyze指令收集的。 除了人為發出analyze指令,openGauss內部也提供了自動analyze的功能。 建議打開autoanalyze和autovacuum的開關。
自動清理
openGauss的儲存引擎還有一個比較特殊的地方,就是update和delete都會保留原元組,作為MVCC的基石。 這種機制會不停產生死元組,並且一直佔據表內的空間。 這種情況下需要vacuum指令來回收這些空間,後續的資料才能使用。 openGauss提供了autovacuum機制,能夠根據表的資料變化量自動觸發vacuum機制,回收死元組。 但是在vacuum受到MVCC機制影響,清理資料會檢查資料庫裡最老的交易。 因此除了開啟autovacuum,還需要控制好資料庫內最長的交易。 所以需要監控pg_stat_activity中xact_start不為空的事務,判斷長事務。 如果遇到一直處於idle in transaction狀態的連接,一定要檢查處理。
安全審計
openGauss資料庫提供了安全性稽核功能,可以設定相關稽核參數,將稽核日誌記錄下來,透過sql函數pg_query_audit查看稽核記錄。
下表展示了審計相關的配置項目。 其中DML操作和SELECT操作審計功能建議關閉,因為審計量太大了。
配置項
描述
使用者登入、登出審計
參數:audit_login_logout 預設值為7,表示開啟使用者登入、登出的稽核功能。 設定為0表示關閉使用者登入、登出的審計功能。 不建議設定0和7之外的值。
資料庫啟動、停止、復原和切換審計
參數:audit_database_process 預設值為1,表示開啟資料庫啟動、停止、復原和切換的稽核功能。
用戶鎖定和解鎖審計
參數:audit_user_locked 預設值為1,表示開啟稽核使用者鎖定和解鎖功能。
使用者存取越權審計
參數:audit_user_violation 預設值為0,表示關閉使用者越權操作審計功能。
授權和回收權限審計
參數:audit_grant_revoke 預設值為1,表示開啟稽核使用者權限授予與回收功能。
資料庫物件的CREATE,ALTER,DROP操作審計
參數:audit_system_object 預設值為12295,表示只對DATABASE、SCHEMA、USER、DATA SOURCE這四類資料庫物件的CREATE、ALTER、DROP操作進行稽核。
具體表的INSERT、UPDATE和DELETE操作審計
參數:audit_dml_state 預設值為0,表示關閉特定表的DML操作(SELECT除外)稽核功能。
SELECT操作審計
參數:audit_dml_state_select 預設值為0,表示關閉SELECT操作審計功能。
COPY審計
參數:audit_copy_exec 預設值為0,表示關閉copy操作審計功能。
預存程序和自訂函數的執行審計
參數:audit_function_exec 預設值為0,表示不記錄預存程序和自訂函數的執行稽核日誌。
SET審計
參數:audit_set_parameter 預設值為1,表示記錄set操作稽核日誌
如果需要針對特殊使用者進行SQL層級的審計,可以使用AUDIT POLICY統一審計方式。 打開enable_security_policy開關統一稽核原則才可以生效。
統一審計預設輸出節點的rsyslog日誌中,在作業系統後台服務設定檔/etc/rsyslog.conf中加入程式碼:
local0.* /var/log/localmessages
執行如下命令:
sudo touch /var/log/localmessages
sudo chmod 600 localmessages
sudo systemctl restart rsyslog
然後透過建立 AUDIT POLICY來實現。
CREATE AUDIT POLICY [ IF NOT EXISTS ] policy_name { { privilege_audit_clause | access_audit_clause } [ filter_group_clause ] [ ENABLE | DISABLE ] };
例如僅審計user1用戶的iud操作:
CREATE AUDIT POLICY adt1 ACCESS INSERT,UPDATE,DELETE FILTER ON ROLES(user1);
監控告警
對於企業級的資料庫部署維警,監控警報和緊急處置處理是最重要的。 對於openGauss的監控告警需要達到的目標是能夠準確發現問題並告警,能夠快速基於監控數據分析根因並處理。 為了達成這個目標,建議openGauss資料庫的監控一方面要全面擷取效能和狀態指標,另一方面對於關鍵指標實現準確警告。
監控
openGauss提供了許多監控視圖。 特別是dbe_perf模式下的監控視圖,內容包括OS、Instance、Memory、File、Object、Workload、Session/Thread、Transaction、Query、Cache/IO、Utility、Lock、Wait Events、Configuration、Operator和Workload Manager等對象 的監控。 這些監控視圖也是WDR報表的快照來源。 建議統一採集這些效能快照視圖數據,透過智慧運維管理和分析。
告警
相對於監控資料收集的全面性,警告指標需要挑選全域有意義的物件。 重要的警告有監控資料庫狀態、主從複製狀態、線上會話數量、等待會話數量、長事務、長SQL、死鎖、回滾語句數等。
備份恢復
openGauss資料庫支援的備份方式還是比較全面的。 而企業級的資料庫在這方面要求也很高。 一方面為了出問題盡快恢復,資料庫定期備份策略都比較激進,另一方面備份過程還要盡量減少效能影響和資源佔用。 例如銀行一般每天都會備份全量資料庫,時刻備份歸檔日誌,為了減少效能影響,備份會選擇從庫執行。 如果是遠端備份,那麼也會採用單獨的備份網段,與生產業務網隔離。
許多國內備份廠商目前也一直在測試備份openGauss資料庫,相信很快就會有類似NBU這樣的備份產品出現,並在企業級應用。 openGauss資料庫支援遠端備份,目前也可以建立基於網路的備份伺服器,透過備份專用網,統一調度管理所有資料庫的備份。
結束語
其實做好openGauss企業級部署,就是拿之前對於Db2和Oracle的運維標準來建置openGauss資料庫的維運體系。 openGauss資料庫技術特性與這些商業資料庫相比差異不大,目前欠缺的也只是生態和產品成熟性。 相信這兩方面會越來越好,因此我對於openGauss資料庫在企業中的應用前景非常看好,也希望其盡快成為一個合格的國產替代品。