原创 李逸皓
伺服器硬體問題
一、網路線故障–丟包–失聯 ==>更換網路線
1. 判斷伺服器是否丟包可以用ping指令偵測伺服器網路是否丟包。
具體做法是:- 登入Linux 伺服器,ping 網關或知名網站位址,如ping www.baidu.com- 加上數目參數,如ping www.baidu.com -c 1000,檢測1000次的丟包情況- 觀察丟包率,如果丟包率較高,說明有丟包問題
2. 網線線序網線有568A和568B兩種線序標準,區別是橙白、綠白、藍、藍白、綠、棕白、棕這7根線的順序不同。 568B: 橘白橙綠白藍藍白綠棕白棕568A: 橘白綠白橙藍藍白綠棕白棕如果機房線纜是568A,伺服器網卡是568B,需要對調橘白、綠白兩對線,使線序一致,否則會導致網路不通。
3. 處理方法如果判斷伺服器網路有丟包問題,可以換用新的網路線測試,若丟包解決,則可以斷定是網路線故障。
二、板載網卡故障—->更換主機板
1. 板載網卡故障如果伺服器板載網卡故障,網卡無法連接網路,可以考慮更換主機板來解決。
2. 使用外接網卡當板載網卡故障時,可以使用外接的萬兆網卡來暫時連接網路。使用方法是:- 安裝網路卡的驅動程式,載入網卡模組- 將網路卡透過PCI-E插槽插入主機板,連接網路線- 設定網路卡IP等網路參數,使其連接網路
3. 使用光纖網路卡對於伺服器間的連接,可以使用光纖網路卡+光模組來實現。將光模組插入網路卡介面,使用光纖線連接到交換器連接埠。
4. 萬兆網路卡速率萬兆網路卡的協商速率最大可達10000Mb/s,約合10Gbps。
5.萬兆網路卡–外接的網路卡–>安裝驅動–>使用光纖+模組
三、CPU(機器裡有幾個CPU)
1. 伺服器CPU數量伺服器可以設定多個CPU。多CPU伺服器可以提供更強大的處理能力。
2. 單一CPU伺服器宕機如果單一CPU伺服器的CPU故障,會導致整台機器宕機和無法啟動。
3. 雙CPU伺服器報錯如果雙CPU伺服器,只有1個CPU故障,由於還有另一個CPU工作,機器不會完全宕機,可以啟動。但會在日誌或螢幕看到報錯訊息,例如CPU1 ERROR。
4. 定位故障CPU根據錯誤訊息中的CPU編號,例如CPU1,可以定位到故障發生在具體哪個CPU,然後可以進行更換。
5. 處理方法處理方法為更換故障CPU,雙CPU伺服器更換1個CPU後可以繼續工作,單CPU伺服器則需要更換CPU後才能恢復。
四、伺服器品牌
1. Dell:戴爾,全球知名的伺服器供應商,產品線齊全,從小型Tower伺服器到大型機架式伺服器均有,如PowerEdge R710是常見的2U機架伺服器。
2. IBM:IBM也是全球伺服器龍頭老品牌,從小型到大型伺服器應有盡有,System X、System Z系列比較知名。
3. HP:惠普,同樣全球知名的伺服器品牌,ProLiant系列較常見。
4. Inspur:浪潮,中國本土伺服器品牌,提供小型到大型伺服器,代表產品如浪潮NF系列機架伺服器。
5. H3C:杭州華三通訊技術有限公司,知名的網路設備供應商,也提供伺服器產品。
6. GD:廣達電腦,台灣知名伺服器OEM生產商,為全球許多品牌生產伺服器。
7. Lenovo:聯想,知名的個人電腦品牌,也生產小型機架式伺服器。
五、內存報錯MEM-(DIMM_A1)
1. 內存錯誤報錯如果伺服器內存條發生故障,會在啟動時報錯,提示具體是哪根內存條出現問題,例如MEM-DIMM_A1 ERROR表示A1內存插槽的內存條故障。
2. 導致的故障現象記憶體故障時,伺服器可能會出現無故障自動重新啟動的情況。且啟動時會卡在BIOS介面,需要按F1才能繼續啟動進入系統。
3. 解決方法可以換裝相同規格的記憶體條進行替換,或者測試拔出故障的記憶體條,讓伺服器運行在減少記憶體的狀況下。
4. 更換注意事項更換記憶體時需注意記憶體型號、容量、速度等參數要匹配,以確保系統穩定運作。
分類: killtest
2024年學習收入最高的程式語言
原创 浮丶云 全栈开发ck
1. Python
Python 是最受歡迎、用途最廣泛的語言之一。它通常用於網頁開發、數據科學、機器學習等。
以下是 Python 程式語言的一些主要用途:Web 開發:Python 廣泛用於 Web 開發,包括前端(客戶端)和後端(伺服器端)。
流行的 Python Web 框架包括 Django、Flask 和 Pyramid。
資料科學與機器學習:Python 擁有強大的資料科學、科學和機器學習資料庫,例如 NumPy、Pandas、Matplotlib、Scikit-learn。它是這些領域最常用的語言之一。
桌面應用程式:Python 可以與 Tkinter、PyQt、Kivy 等程式庫一起使用,為 Linux、Windows、macOS 建立桌面應用程式。例如 IDE、實用程式、遊戲。
後端開發:Python 為許多流行的網站和應用程式提供支援。它在使用 Django 或 Flask 建立的網站中用作伺服器端語言。
科學和數值計算:Python 的 NumPy 和 SciPy 庫使其非常適合科學計算、模擬、數值分析和計算科學。
自動化和腳本編寫:Python 通常用於自動執行重複性任務並透過腳本將各種應用程式黏合在一起。
遊戲開發:Python 使用 PyGame、Kivy、Pyglet 和 Ren’Py 等函式庫進行遊戲開發越來越受歡迎。
網頁抓取:Beautiful Soup、Scrapy 等程式庫使 Python 非常適合抓取網頁和提取結構化資料。
系統腳本:Python 可用於自動化系統管理任務,使用 Ansible、SaltStack 等工具將基礎架構作為程式碼進行管理。
GUI 程式設計:Tkinter 與 Python 捆綁在一起。 PyQt 和 Kivy 也是 GUI 應用程式的熱門選擇。
總而言之,資料科學、網頁開發、自動化、科學計算是 Python 的一些主要領域。
平均工資為105,000美元。
2. Java
Java 是使用最廣泛的程式語言之一。它通常用於後端 Web 開發、Android 應用程式開發和企業應用程式。
以下是有關 Java 及其常見用例的一些關鍵知識:
Java 是一種通用的、基於類別的、物件導向的程式語言,由 Sun Microsystems(現為 Oracle Corporation)於 1995 年創建。
Java 程式通常被編譯為可以在任何 Java 虛擬機器 (JVM) 上運行的字節碼,無論電腦體系結構如何。這種「一次編寫,隨處運作」的特性是 Java 的最大優點之一。
Java 的一些主要用例包括企業應用程式、Android 應用程式、後端 Web 開發、桌面應用程式、大數據等。企業應用程式-
Java因其穩健性、安全性和可移植性而被廣泛用於開發企業軟體,如ERP系統、銀行應用程式等。
Android 開發 — Android 基於 Java 程式語言,並具有 Java SE 平台的改編版本。
Java 用於建立 Android 應用程式。
Web 開發 — Java 用於透過 Spring、Hibernate、Struts 等框架建立伺服器端應用程式。它也用於透過 Quarkus 等框架建立無伺服器功能。
桌面應用程式 — Java Swing 和 JavaFX 允許為 Windows、Linux 和 macOS 建立基於 GUI 的桌面應用程式。
大數據-由於其效能和可擴展性,Java 通常用於透過 Hadoop 和 Spark 等框架進行大數據處理。遊戲開發-Java 用於開發遊戲,特別是針對使用 LibGDX 和 JavaFX 等框架的瀏覽器。
平均工資為10萬美元。
3. C#
C# 是一種流行的 Microsoft 支援的語言,通常用於 Windows 桌面和行動應用程式、Unity 遊戲開發以及使用 .NET 進行後端 Web 開發。
以下是有關 C# 程式設計及其常見用例的關鍵知識:C#(發音為 C Sharp)是 Microsoft 開發的多範式程式語言。它是一種類似 C 和 C++ 的物件導向語言,但更簡單。
C# 程式碼被編譯為一種稱為 Microsoft 中間語言 (MSIL) 的中間語言,該語言在 .NET Framework 上執行。這使得 C# 程式可以在任何支援 .NET 的作業系統上運行。
C# 的一些主要用例包括 Windows 桌面應用程式、Web 開發、遊戲、行動應用程式、機器學習等。
Windows 桌面應用程式 — C# 通常透過 Windows Presentation Foundation (WPF) 和 Windows 窗體用於建立 Windows 桌面應用程式。
Web 開發 — ASP.NET 和 Mono 等流行框架允許使用 C# 建立 Web API、網站和服務。
遊戲開發 — C# 廣泛用於透過 Unity 等引擎開發 Windows、Xbox、行動裝置的遊戲。
行動應用程式 — Xamarin 允許使用 C# 為 Android 和 iOS 建立跨平台行動應用程式。
機器學習 — C# 用於透過 ML.NET、TensorFlow Sharp 等程式庫建置和部署 ML 模型。
雲端/Web 服務 — C# 非常適合使用 .NET Core 等框架建立基於雲端的微服務和無伺服器功能。
桌面/行動庫 – C# 允許為 GUI、資料存取等任務建立可重複使用的庫。
平均工資為95,000美元。
4. C++
C++ 是一種低階系統程式語言,通常用於遊戲、作業系統、驅動程式和嵌入式系統等效能關鍵型應用程式。
以下是有關 C++ 及其常見用例的關鍵知識:C++是一種高效、靈活、低階的通用程式語言。
它於 1979 年作為 C 語言的擴展而開發。
C++ 支援過程式、物件導向和泛型程式設計。它具有類別、繼承、模板、異常等功能。
C++ 程式碼通常被編譯為機器碼以獲得最大效能。它允許直接存取內存,這使其適合系統編程。
C++ 的一些主要用例包括系統程式設計、遊戲開發、嵌入式系統、桌面應用程式等。
系統程式設計-C++ 由於其效率和低階存取而被廣泛用於開發作業系統、資料庫、編譯器、裝置驅動程式。
遊戲開發-大多數 AAA 遊戲都是使用 C++ 開發的,因為它具有高效能和與圖形庫互動的能力。
嵌入式系統 — C++ 由於其低階功能而通常用於對微控制器、硬體、韌體進行程式設計。
桌面應用程式 — C++ 與 Qt、wxWidgets 允許為 Windows、Linux 建立高效能桌面應用程式。
後端開發 — C++ 因其效率而為許多 Web 伺服器和網路應用程式提供支援。
科學/數值計算-Boost 和 Eigen 等函式庫使 C++ 非常適合科學和工程任務。
平均工資為92,000美元。
5. JavaScript
JavaScript 是網路的主要程式語言。它通常用於前端 Web 開發和 Node.js 後端開發。
以下是有關 JavaScript 及其常見用例的關鍵知識:
JavaScript 是一種動態、弱型且基於原型的腳本語言。它最初的設計目的是為網頁添加互動性。 JavaScript 程式碼直接在瀏覽器中在用戶端執行,以提供動態和互動式行為,例如表單驗證、動畫、AJAX 呼叫等。隨著 Node.js 的出現,JavaScript 也可以在伺服器端用於 Web 開發和建立網路應用程式。
JavaScript 的一些主要用例包括:
前端 Web 開發 — 用於透過瀏覽器為網頁添加互動性和動態行為。
後端 Web 開發 — 透過 Node.js,JavaScript 可用於建立伺服器、Web API 和網路應用程式。
桌面應用程式-借助 Electron 等框架,JavaScript 可以將 Web 應用程式打包成獨立的桌面應用程式。
行動應用程式-React Native 允許使用 JavaScript 建立跨平台行動應用程式。
遊戲開發-Phaser 和 Babylon.js 等流行框架使用 JavaScript 來開發遊戲。
全端開發-JavaScript 可以與 Express、React 等框架從前端到後端到端地使用。
物聯網/嵌入式系統-JavaScript 透過 Node.js 在各種裝置和微控制器上運作。
平均工資為90,000美元。
6. PHP
PHP 是一種流行的伺服器端腳本語言,通常用於建立內容管理系統和其他資料庫驅動的網站。
以下是 PHP 及其常見用例的關鍵知識:
PHP 是一種廣泛使用的開源腳本語言,可以嵌入到 HTML 程式碼中以建立動態 Web 應用程式。
它最初是為 Web 開發而創建的,用於生成動態頁面內容,但現已發展為通用程式語言。
PHP 程式碼在伺服器端運行並產生 HTML,然後傳送到客戶端。它通常與 MySQL 一起用於資料庫連接。
PHP 的一些主要用例包括:
內容管理系統 — PHP 為 WordPress、Drupal、Joomla 等流行的 CMS 平台提供支援。
電子商務網站 — 使用 Magento、OpenCart、Prestashop 等平台建立的商店廣泛使用 PHP。
自訂 Web 應用程式 — PHP 用於建立自訂資料庫驅動的網站和 Web 應用程式。
Web 服務 — 它可用於建立 RESTful API 和 SOAP Web 服務。
Web 框架-Laravel、Symfony、CakePHP 等流行的 PHP 框架簡化了開發。
桌面應用程式 — PHP GTK 允許建立可以捆綁 Web 應用程式的桌面應用程式。
Web 腳本-通常用於伺服器端腳本任務,例如表單處理、使用者驗證等。
平均工資為85,000美元。
7. Swift
Swift 是 Apple 用於建立 iOS 和 macOS 應用程式的主要程式語言。這是一個越來越受歡迎的選擇。
以下是有關 Swift 及其常見用例的關鍵知識:
Swift 是 Apple 開發的通用程式語言,於 2014 年首次推出。它的設計比 Objective-C 更現代、更有彈性和更具互動性。
Swift 程式碼直接編譯為機器碼,使其比解釋語言更快。它是完全開源的,可與 Apple 的 Cocoa 和 Cocoa Touch 框架配合使用。 Swift 的主要用例是為 iOS、iPadOS、macOS、watchOS 和 tvOS 等 Apple 平台開發應用程式和遊戲。
iOS/iPadOS 應用程式開發 – Swift 是 Apple 推薦的用於為 iPhone 和 iPad 建立本機行動應用程式的主要語言。
macOS 應用程式開發 – Swift 允許為 macOS 建立桌面應用程式和命令列工具。
watchOS 應用程式開發 — 用於為 Apple Watch 作業系統建立應用程式。
tvOS 應用程式開發 — Swift 為 Apple TV 開發的應用程式提供支援。
透過 SwiftUI 實現跨平台 — 新的 SwiftUI 框架允許建立跨平台工作的 UI。
後端 Web 服務 – Swift 可以與 Vapor 和 Kitura 等伺服器端框架一起使用來建立 API。
遊戲開發-SpriteKit 和 SceneKit 等遊戲引擎使用 Swift 來開發 Apple 平台上的遊戲。
平均工資為83,000美元。
8. R
R 是一種統計程式語言,通常用於資料分析、視覺化和機器學習。它在科學、研究和金融等領域很受歡迎。
以下是有關 R 程式語言及其常見用例的關鍵知識:
R 是一種用於統計分析、圖形和統計計算的程式語言和軟體環境。它主要用於開發統計軟體和數據分析。
R 是 20 世紀 90 年代初由貝爾實驗室的統計學家 John Chambers 及其同事開發的。
R 的一些主要用例包括:資料分析和視覺化:R 擁有廣泛的統計和圖形技術,用於分析、視覺化和建模資料。
機器學習:流行的 R 軟體包(如 caret、rpart、randomForest)廣泛用於機器學習領域,如預測建模、分類、聚類等。
統計計算:R的核心功能包括統計技術,如描述性統計、假設檢定、迴歸、時間序列分析等。
金融:R廣泛應用於金融數據分析、風險管理、投資組合最佳化、交易演算法等。
生物資訊學:像 Bioconductor 這樣的軟體套件可以在生物資訊學中分析基因表現、DNA 序列、蛋白質結構。
社會科學:用於社會學、心理學、地理學等領域的調查分析、心理測量、空間資料分析。
學術界:R 在統計學教學中很受歡迎,並且作為經濟、醫學、工程等領域的研究工具。
平均工資為80,000美元。
9. Go
Go(也稱為 Golang)是 Google 開發的一種系統程式語言。它通常用於建立微服務、網路工具和其他後端應用程式。
以下是有關 Go 程式語言及其常見用例的關鍵知識:
Go(也稱為 Golang)是 Google 於 2007 年開發的一種靜態類型、編譯型程式語言。它旨在建立簡單、可靠和高效的軟體。
Go 的一些主要用例包括:
後端 Web 開發:Go 的並發特性使其非常適合建立可擴展的 Web 應用程式和伺服器。
流行的 Web 框架包括 Gin、Echo 等。微服務:由於輕量級流程和易於部署,Go 擅長開發微服務。
系統程式設計:Go因其效率和對資源的控製而在作業系統、檔案系統、資料庫等中得到應用。
網路應用:由於對並發網路的良好支持,它通常用於網路工具、伺服器、協定。
雲端開發:Go 非常適合開發基於容器的雲端應用程式、AWS Lambda 上的無伺服器函數等。
DevOps 工具:許多 DevOps 工具(例如 Docker、Kubernetes、Terraform、Prometheus 等)都使用 Go。
分散式系統:諸如 goroutine、通道之類的功能有助於在 Go 中輕鬆建立分散式和並發應用程式。
桌面應用程式:GTK 綁定允許為 Linux、Windows 等開發基於 GUI 的桌面程式。
平均工資為78,000美元。
10. Scala
Scala 是一種運行在 Java 虛擬機器 (JVM) 上的函數式程式語言。它通常用於大數據處理、機器學習和後端 Web 開發。
以下是 Scala 程式語言及其常見用例的關鍵知識:
Scala 是一種在 Java 虛擬機器 (JVM) 上運行的通用程式語言。它是一種結合了物件導向和函數式程式設計原理的混合語言。
Scala 程式碼編譯為 JVM 字節碼,因此它可以與現有 Java 程式碼和函式庫互動。
它是靜態類型的,旨在比 Java 更簡潔、更安全。
Scala 的一些主要用例包括:
大數據處理:Scala因其在JVM上的效能而被廣泛用於Spark、Kafka等框架的大規模資料處理。
Web 開發:Play 等流行框架允許使用 Scala 建立 Web 應用程式和服務。
雲端應用程式:Scala 非常適合 AWS、GCP 等上的無伺服器/微服務架構。
機器學習:Breeze、Spark ML 等函式庫支援在 Scala 中進行 ML/深度學習模型開發。
桌面應用程式:Swing 和 JavaFX 綁定為 Scala 桌面應用程式提供 GUI 支援。
金融應用:金融機構普遍採用Scala來處理涉及高效能運算的項目。
並發性:參與者模型等特性使Scala非常適合編寫並發和平行程式。
平均工資為 75,000 美元。
交換機三種連接方式:級聯,堆疊和集群
交換器的連接方式大家應該都知道,一共有三種,分別是:級聯、堆疊和叢集。今天, 大家就詳細討論一下交換器的這三種連接方式及彼此間的差別吧!
交換器的級聯技術一般用來實現多台交換器之間的互連接;堆疊技術用來將多台交換器組成一個單元,從而提高更大的端口密度和更高的性能;集群技術用來將相互連接的多台交換器作為一個邏輯設備進行管理,從而降低網路管理成本,簡化管理操作。
01 級聯級聯可以定義為兩台或兩台以上的交換器透過一定的方式相互連接。根據需要,多台交換器可以以多種方式進行級聯。在較大的區域網路例如校園網路中,多台交換器依照效能和用途一般形成匯流排型、樹型或星型的級聯結構。
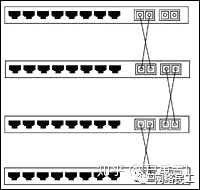
城域網路是交換器級聯的絕佳範例。目前各地電信部門已經建置了許多市地級的寬頻IP城域網路。這些大款城域網路自上向下一般分為3個層次:核心層、匯聚層、接取層。核心層一般採用千兆乙太網路技術、匯聚層採用1000M/100M 乙太網路技術,接取層採用100M/10M 乙太網路技術,所謂 “千兆到大樓,百兆到樓層,十兆到桌面 ” 。
這種結構的寬頻城域網路其實就是由各層級的許多台交換器級聯而成的。核心交換機(或路由器)下連若干台匯聚交換機,匯聚交換機下聯若干台小區中心交換機,小區中心交換機下連若干台樓宇交換機,樓宇交換機下連若干台樓層(或單元)交換機(或集線器)。
交換器一般是透過普通用戶連接埠進行級聯,有些交換器則提供了專門的級聯連接埠。這兩種連接埠的差異僅在於一般連接埠符合MDI 標準,而級聯連接埠 ( 或稱為上行口 ) 符合 MDIX標準。由此導致了兩種方式下接線方式不同:當兩台交換器都通過普通端口級聯時, 端口間電纜採用直通電纜(Straight Throurh Cable) ;當且僅當中一台通過級聯端口時,採用交叉電纜(Crossover Cable) 。
為了方便進行級聯,某些交換器上提供了一個兩用連接埠(MDI 或MDIX),可以透過開關或管理軟體將其設定為MDI(MDI是正常的UTP或STP連接) 或MDIX(連接器的傳送和接收對是在內部反接的,這就使得不同的設備(如集線器-集線器或集電器-交換機),可以利用常規的UTP或STP電纜實現背靠背的級聯)方式。更進一步,某些交換器上全部或部分連接埠具有 MDI/MDIX 自校準功能,可自動區分網路線類型,進行連鎖時更方便。
進行級聯的時候需要注意,原則上任何廠商、任何型號的乙太網路交換器均可進行級聯,單頁不排除在一些特殊情況下兩台交換器無法進行級聯。交換器間級聯的層數是有一定限度的。成功實現級聯的最根本原則就是任兩個站點之間的距離不能超過媒體段的最大跨距。多台交換器級聯時,應確保它們都支援生成樹協議,既要防止網內出現環路,又要允許冗餘鏈路存在。
進行級聯時,應盡力確保交換器間的中繼鏈路具有足夠的頻寬,為此可採用全雙工技術和鏈路匯聚技術。交換器埠採用全雙工技術後,不但對應埠的吞吐量加倍,而且交換器間終極距離大大增加,使得異地分佈、距離較遠的多台交換器級聯成為可能。鏈路匯聚也稱為連接埠匯聚、連接埠捆綁、連結擴容組合,由IEEE802.3ad 標準定義。即兩台設備之間透過兩個以上的同種類型連接埠並進行連接,同時傳輸數據,以便提供更高的頻寬、更好的冗餘度以及實現負載平衡。
需要注意的是,並非所有類型的交換器都支援這兩種技術。
02堆疊堆疊是指將一台以上的交換機組合起來共同工作,以便在有限的空間內提供盡可能多的端口多台交換機經過堆疊形成一個堆疊單元,可堆疊的交換機性能指標中有一個“最大可堆疊數”,它指的就是一個堆疊單元中所能堆疊的最大交換機數,代表一個堆疊單元中多能提供的最大端口密度。
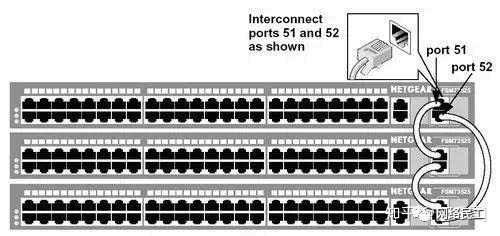
堆疊與級聯這兩個概念既有區別又有連結。堆疊可以看作是級聯的特殊情況。它們的不同之處在於:級聯的交換器之間可以相距很遠(在媒體許可範圍內),而一個堆疊單元內的多台交換機之間的距離非常近,一般不超過幾米;級聯一般採用普通端口,而堆疊一般採用專用的堆疊模組和堆疊電纜。一般來說,不同廠商、不同型號的交換器可以互相級聯,堆疊則不同,它必須在可堆疊的同類型交換機之間進行;級聯僅僅是交換器之間的簡單連接,堆疊則是將整個堆疊單元作為交換器來使用,這不僅意味著連接埠密度的增加,而且意味著系統頻寬的加寬。
目前,市場上的主流交換器可以細分為可堆疊型和非堆疊型兩大類。而號稱可以堆疊的交換器中,又有虛擬堆疊和真正堆疊之分。所謂的虛擬堆疊,實際上就是交換器之間的級聯。交換器並不是透過專用堆疊模組和堆疊電纜,而是透過Fast Ethernet 連接埠或 Giga Ethernet 連接埠進行堆疊,實際上就是一種變相的級聯。即便如此,虛擬堆疊的多台交換器多台交換器在網路中已經可以作為一個邏輯設備進行管理,從而使網路管理變得簡單起來。真正意義上的堆疊需要滿足:採用專用堆疊模組和堆疊總線進行堆疊,不佔用網路端口,多台交換器堆疊後,具有足夠的系統頻寬,從而確保堆疊後每個端口仍能達到線速交換;多台交換器堆疊後, VLAN等功能不受影響。
目前市面上有相當一部分可堆疊的交換器屬於虛擬堆疊類型而非真正堆疊類型。很顯然,真正意義上的堆疊比虛擬堆疊在性能上要高出許多,但採用虛擬堆疊至少有兩個好處:虛擬堆疊往往採用標準Fast Ethernet 或Giga Ethernet 作為堆疊總線, 易於實現,成本較低;堆疊連接埠可以作為普通連接埠使用, 有利於保護用戶投資。採用標準 Fast Ethernet 或 Giga Ethernet連接埠實現虛擬堆疊,可以 大幅延伸堆疊的範圍 ,使得堆疊不再局限於一個機櫃之內。
堆疊可以大大提高交換器連接埠密度和效能。堆疊單元具有足以匹敵大型機架式交換器的端口密度和性能, 而投資卻比機架式交換機便宜得多 ,實現起來也靈活得多。這就是堆疊的優勢。
機架式交換器可以說是堆疊發展到更高階段的產物。機架式交換機一般屬於部門以上級別得交換機,它有多個插槽,連接埠密度大,支援多種網路類型,擴充性較好,處理能力強,但價格昂貴。
03集群所謂集群,就是將多台互相連接(級聯或堆疊)的交換器作為一個邏輯設備進行管理。急群眾,一般只有一台起到管理作用的交換機,成為命令交換機,它可以管理若干台其他交換機。在網路中,這些交換器只需要佔用一個IP位址節約了IP位址。在命令交換機統一管理下,集群中多台交換器協同工作,大幅降低管理強度。

例如, 管理員只需要透過命令交換器就可以對叢集中所有交換器進行版本升級。
集群技術為網路管理工作帶來的好處是毋庸置疑的。但要使用這項技術,應當注意到,不同廠商對集群有不同的實現方案, 一般廠商都是採用專有協議實現集群的 。這決定了集群技術有其限制。不同廠商的交換器可以級聯,但不能集群。即使同一廠商的交換機,也只有指定的型號才能實現集群 。